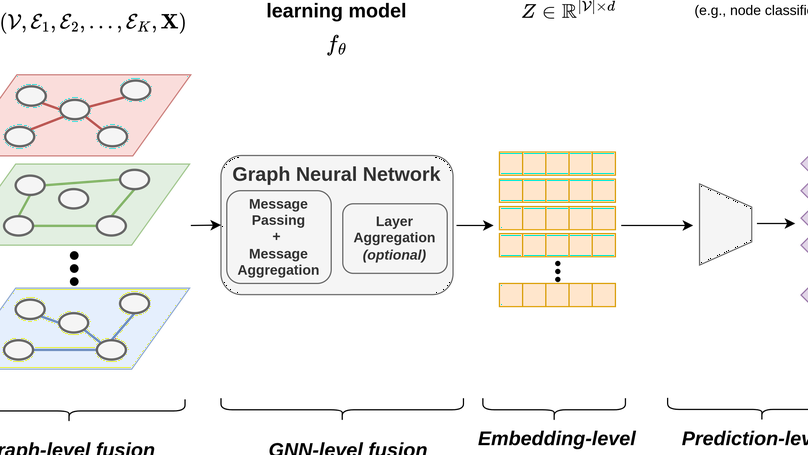
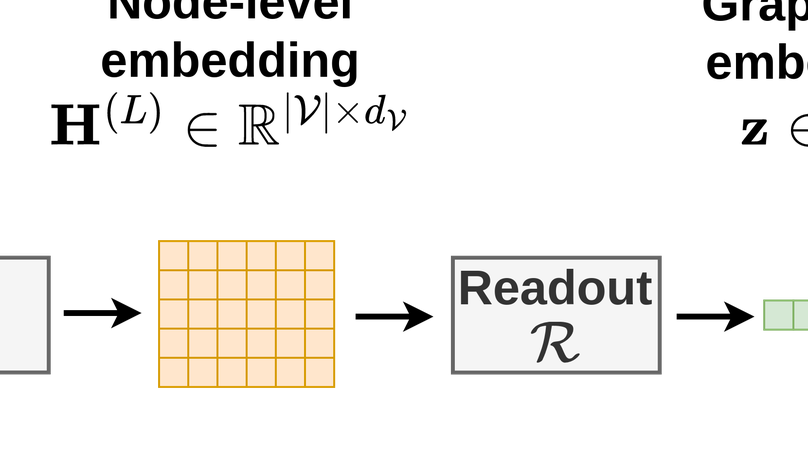
Graph machine learning models have been successfully deployed in a variety of application areas. One of the most prominent types of models - Graph Neural Networks (GNNs) - provides an elegant way of extracting expressive node-level representation vectors, which can be used to solve node-related problems, such as classifying users in a social network. However, many tasks require representations at the level of the whole graph, e.g., molecular applications. In order to convert node-level representations into a graph-level vector, a so-called readout function must be applied. In this work, we study existing readout methods, including simple non-trainable ones, as well as complex, parametrized models. We introduce a concept of ensemble-based readout functions that combine either representations or predictions. Our experiments show that such ensembles allow for better performance than simple single readouts or similar performance as the complex, parametrized ones, but at a fraction of the model complexity.